/CCITTFaxDecode and the actual CCITT (Group 4) decoding algorithm
TLDR: If your internet searches for “CCITTFaxDecode” don’t give results of much relevance, try searching for “CCITT” along with “group 4”, etc.
Inside a PDF file you may encounter parts that are compressed and meant to be uncompressed (decoded) with the /CCITTFaxDecode filter.
This “CCITTFaxDecode” (see section 3.3.5 of the PDF reference) refers to the “CCITT facsimile (fax) encoding”, itself an informal name for “Recommendations T.4 and T.6 of the International Telecommunications Union (ITU)”. It also happens to be used as one of the possible compression options in TIFF files, but is not otherwise connected to TIFF.
What is the CCITT Group 4 encoding?
Suppose you have a monochrome (aka bitonal, aka black-and-white) bitmap image, i.e. a sequence of 0s and 1s, like the following crude drawing of the digit “3”:
0111110
0000010
0011110
0000010
0111110
(Or more realistically, the data from a black-and-white scan of a piece of paper, being done inside a fax machine.) The goal is to compress it.
The CCITT algorithm is an ad-hoc encoding scheme that is intended to achieve somewhat reasonable compression for typical documents.
There are actually a few schemes, with names like “Group 3” (itself in multiple variants) and “Group 4”, but because Group 4 is what I encountered and care about right now, I’ll only focus on Group 4.
There are basically two ideas:
- Each scanline (e.g. each row in the example above) tends to have runs of 0s and runs of 1s, so we can encode the run lengths. (Used in both
- Each scanline tends to be similar to the one just above, so we can encode the differences.
For example, we could just describe the positions of where each run begins (called the “changing element”). And we could describe these positions either relative to the previous changing element in the same line (the length of the run, basically) or relative to a changing element in the previous line (“vertical mode coding”). This is precisely what the Group 4 (aka G42D) scheme does. Here’s a figure from the official documentation:
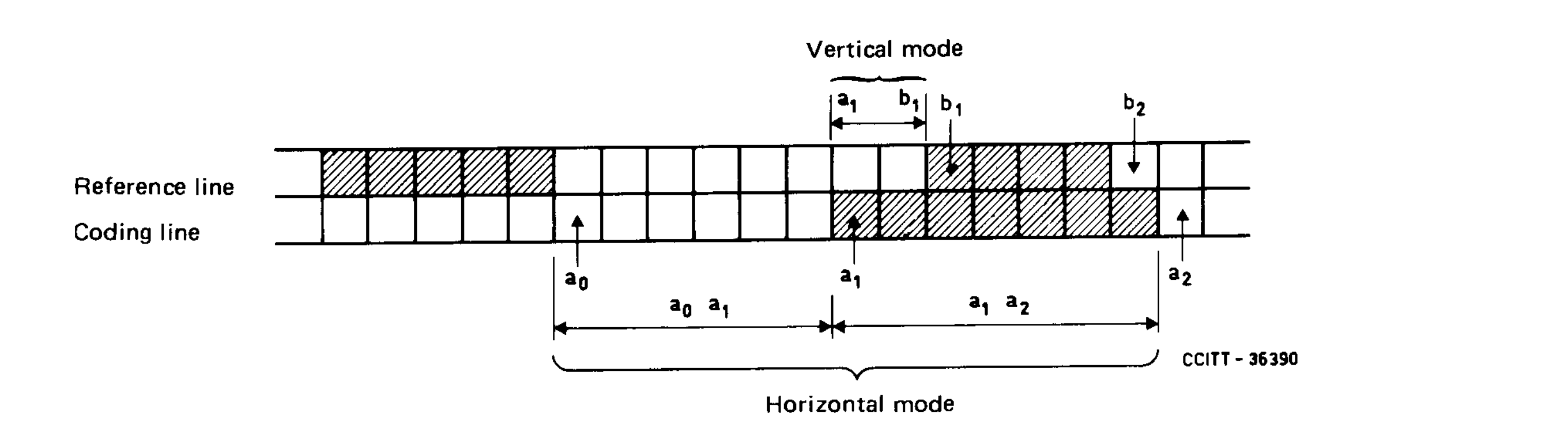
When we’re at a0 and want to describe the position of a1, either
- a1 is very close to b1 (absolute difference 3 or less), in which case we describe a1 as {0, 1, 2, 3, -1, -2, -3} pixels away from b1, with a specific code for each of the 7 cases. (called “vertical mode coding”), or
- a1 is to the right even of b2, in which case we record it as a “pass” and pretend that a0 is now just below b2,
- else we record the offsets of a1 and a2 using the run lengths (called “horizontal mode coding”)
How to decode?
The encoding scheme is quite clearly described in the official reference (linked below), if you read past the first page of officialese. I almost started writing my own decoding program, but after seeing a few code examples (also linked below), decided that it was unnecessary.
Instead a trick can be used: as TIFF files can contain data compressed by CCITT Group 4 (or “CCITT T.6 bi-level encoding”), we can, by wrapping our data in an appropriate header, treat it as a TIFF file! If the data happens to be image data (which is likely true in trusted, non-malicious cases), then we can use all the tools that work with TIFF files to extract our image into other formats.
And indeed such code is much easier to write. Using code snippets by Sergey Shashkov (see e.g. here, here, here), we can do something like the following:
import struct
def tiff_header_for_CCITT(width, height, img_size, CCITT_group=4, blackIsZero=False):
"""Returns the appropriate header that will make it a valid TIFF file."""
tiff_header_struct = '<' + '2s' + 'h' + 'l' + 'h' + 'hhll' * 8 + 'h'
return struct.pack(tiff_header_struct,
b'II', # Byte order indication: Little-endian
42, # Version number (always 42)
8, # Offset to first IFD
8, # Number of tags in IFD
256, 4, 1, width, # ImageWidth, LONG, 1, width
257, 4, 1, height, # ImageLength, LONG, 1, length
258, 3, 1, 1, # BitsPerSample, SHORT, 1, 1
259, 3, 1, CCITT_group, # Compression, SHORT, 1, 4 = CCITT Group 4 fax encoding
262, 3, 1, int(blackIsZero), # Threshholding, SHORT, 1, 0 = WhiteIsZero
273, 4, 1, struct.calcsize(tiff_header_struct), # StripOffsets, LONG, 1, len of header
278, 4, 1, height, # RowsPerStrip, LONG, 1, length
279, 4, 1, img_size, # StripByteCounts, LONG, 1, size of image
0 # last IFD
)
def decode_ccitt_data(data, width, height, CCITT_group=4, blackIsZero=False):
"""Decodes CCITT-encoded data, if its intended width, height, etc are known."""
img_size = len(data)
tiff_header = tiff_header_for_CCITT(width, height, img_size, CCITT_group)
return tiff_header + data
def decode_cccitt_data_to_file(data, width, height, out_filename, CCITT_group=4, blackIsZero=False):
with open(out_filename, 'wb') as img_file:
img_file.write(decode_ccitt_data(data, width, height, CCITT_group, blackIsZero))
One of the future posts will show an example where this trick was useful.
Edit: When you extract the original images from a PDF with pdfimages -all (e.g. pdfimages -all foo.pdf foo-img), then pdfimages may create some .ccitt and .params files. They can then be converted to (enclosed in) TIFF with something like:
fax2tiff $(cat foo-img-000.params) foo-img-000.ccitt -o out.tiff
or in a loop:
for f in *.ccitt; do g=$(basename $f .ccitt); echo $g; fax2tiff $(cat $g.params) $f -o $g.tiff; done
Links (in addition to those above)
References:
- (very short: just mentions the two basic ideas) http://www.graphicsacademy.com/what_group4.php
- (short: puts in context w.r.t other schemes, where it’s used etc) https://en.wikipedia.org/w/index.php?title=Group_4_compression&oldid=784092961
- (long: lots of detail on G31D, brief on G42D) https://www.fileformat.info/mirror/egff/ch09_05.htm (from “Encyclopedia of Graphics File Formats”, originally 1994)
- (the official documentation/definition: 11 pages PDF) https://www.itu.int/rec/T-REC-T.6/en -> https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-T.6-198811-I!!PDF-E&type=items
Code examples of decoders:
- CCITT decoder in Python (part of peepdf)
- CCITT decoder in Java: search for “CCITTFaxDecoder.java” for example. Usage examples in “CCITTFaxDecode.java”.
Decoding using TIFF:
- (using TIFF libraries as a way for decoding CCITT) https://www.imagemagick.org/discourse-server/viewtopic.php?t=25503
References less directly useful:
- (some bite-sized posts on a great and useful blog) https://blog.idrsolutions.com/?s=CCITT
- (someone’s slides on Fax image compression; interesting history and details) http://cs.haifa.ac.il/~nimrod/Compression/Image/I1fax2009.pdf
(Thanks for reading! If you have any feedback or see anything to correct, contact me or edit this page on GitHub.)